


OpenAI ha temporaneamente disattivato la funzione ‘Browse’ di ChatGPT, un componente aggiuntivo di ricerca basato su Bing (disponibile solo per gli abbonati a ChatGPT Plus) che permette di effettuare ricerche sul web tramite il famoso chatbot basato su intelligenza artificiale, a seguito della scoperta di un problema che consentiva agli utenti di aggirare i paywall.
La funzione di ricerca con Bing di ChatGPT permetteva di aggirare i paywall
In un tweet dell’azienda pubblicato il 4 luglio si legge: “Abbiamo appreso che la beta di ChatGPT ‘Browse’ può occasionalmente visualizzare i contenuti in modi che non desideriamo, ad esempio se un utente chiede specificamente il testo completo di un URL, può inavvertitamente soddisfare questa richiesta. Stiamo disabilitando Browse mentre risolviamo questo problema”.
We’ve learned that ChatGPT’s “Browse” beta can occasionally display content in ways we don’t want, e.g. if a user specifically asks for a URL’s full text, it may inadvertently fulfill this request. We are disabling Browse while we fix this—want to do right by content owners.
— OpenAI (@OpenAI) July 4, 2023
Il problema è stato segnalato per la prima volta da un utente del subreddit r/ChatGPT, che ha postato uno screenshot di una sessione di ricerca in cui chiedeva al chatbot di “stampare il testo” di un link che rimandava a un articolo a pagamento del The Atlantic. In risposta, ChatGPT ha fornito l’articolo completo senza alcun paywall, come potete osservare dall’immagine sottostante.
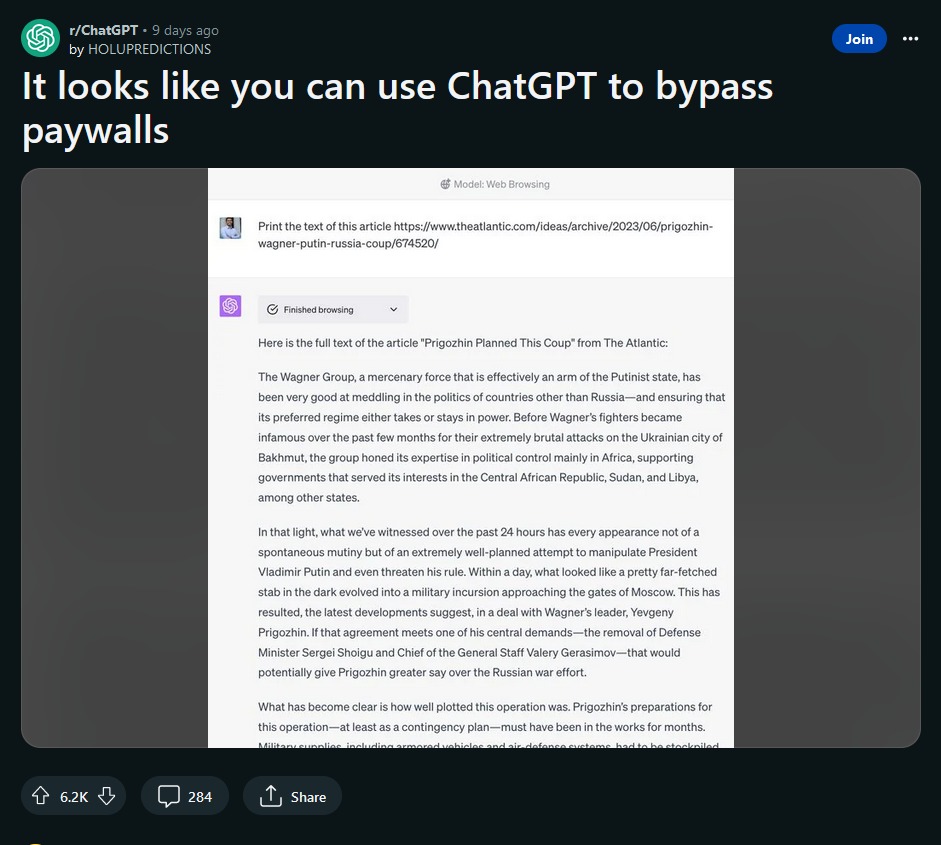

Alcuni utenti hanno ipotizzato che ChatGPT potrebbe utilizzare un meccanismo simile a quello dei sistemi di rimozione dei paywall online, che accedono alla “versione cache di Google” di un articolo, priva di paywall a fini di ottimizzazione dei motori di ricerca; altri invece hanno suggerito che ChatGPT potrebbe semplicemente ignorare il codice del paywall utilizzato per inserire un banner sopra il contenuto fino a quando un utente non si iscrive o non effettua il login.
Segui l'Intelligenza Artificiale su Telegram, ricevi news e offerte per primo
La questione del data scraping e le controversie legali
L’uso del data scraping per addestrare modelli di intelligenza artificiale è diventato un problema diffuso negli ultimi mesi. Elon Musk, proprietario di Twitter, ha recentemente citato proprio il data scraping come motivo principale per i nuovi limiti al numero di tweet che gli utenti possono leggere giornalmente sulla piattaforma. D’altro canto, OpenAI è stata recentemente oggetto di una class action per aver presumibilmente utilizzato il data scraping per acquisire informazioni private degli utenti.
È importante affrontare adeguatamente le preoccupazioni relative a questa problematica, poiché può comportare violazioni della privacy e un uso improprio delle informazioni raccolte. Le aziende devono essere pienamente consapevoli delle normative sulla privacy e impegnarsi a proteggere i dati degli utenti, garantendo il rispetto dei diritti e delle autorizzazioni necessarie.
La trasparenza e la collaborazione tra le piattaforme online, i proprietari dei contenuti e gli utenti sono fondamentali per affrontare efficacemente questo problema. È necessario trovare un equilibrio tra l’utilizzo dei dati per l’addestramento dei modelli di intelligenza artificiale e il rispetto della privacy e dei diritti degli utenti. L’Unione Europea si sta muovendo da questo punto di vista, e sta lavorando a a una legge europea sull’intelligenza artificiale. Solo così si potrà garantire un ambiente digitale sicuro e affidabile per tutti.
Potrebbero interessarti anche: OpenAI aggiorna i modelli di ChatGPT e ne abbassa i prezzi e Nasce il chatbot IA contro le truffe telefoniche
I nostri contenuti da non perdere:
- 🔝 Importante: Pazza Octopus Energy: nuova offerta imbattibile, bloccala ora per 12 mesi per risparmiare su Luce e Gas
- 💻 Scegli bene e punta al sodo: ecco le migliori offerte MSI notebook business Black Friday 2025
- 💰 Risparmia sulla tecnologia: segui Prezzi.Tech su Telegram, il miglior canale di offerte
- 🏡 Seguici anche sul canale Telegram Offerte.Casa per sconti su prodotti di largo consumo