


Meta ha annunciato l’introduzione dei primi modelli Llama quantizzati, progettati per essere eseguiti su molti dispositivi mobili comuni, sfruttando una tecnologia avanzata che riduce il consumo di memoria e accelera notevolmente i tempi di elaborazione. Questi modelli, disponibili nelle versioni da 1B e 3B (ovvero 1 e 3 miliardi di parametri), sono i più piccoli della gamma Llama ma segnano un importante passo avanti verso l’accessibilità di AI avanzate anche su dispositivi con risorse limitate.
In particolare i modelli quantizzati Llama offrono una riduzione media del 56% delle dimensioni rispetto al formato BF16 e una riduzione del 41% dell’uso di memoria. In termini di prestazioni, consentono una velocità di esecuzione di 2-4 volte rispetto ai modelli originali. Grazie a questi miglioramenti, ora è possibile utilizzare Llama su CPU Arm integrate in SoC come Qualcomm e MediaTek, aprendo la strada a un’adozione sempre più ampia in dispositivi mobili e soluzioni edge.
La tecnologia dietro la quantizzazione: QLoRA e SpinQuant
La riduzione di dimensioni e la maggiore efficienza dei nuovi modelli è stata possibile grazie all’uso di due tecniche di quantizzazione avanzate. La prima, Quantization-Aware Training (QAT) con adattatori LoRA (QLoRA), permette di preservare la precisione operativa dei modelli anche in ambienti a bassa precisione. In questo processo, si usa una tecnica di fine-tuning supervisionato che, una volta integrata, consente di mantenere il massimo livello di accuratezza possibile. Questo metodo rappresenta la migliore opzione per la qualità delle prestazioni.
La seconda tecnica, SpinQuant, è una soluzione post-training per la quantizzazione dei modelli, ideale per situazioni in cui l’accesso ai dataset di addestramento è limitato. Pur essendo meno precisa rispetto a QLoRA, SpinQuant è una scelta molto versatile e facile da implementare per i developer che desiderano adattare i modelli Llama a diverse architetture hardware senza la necessità di risorse computazionali elevate.
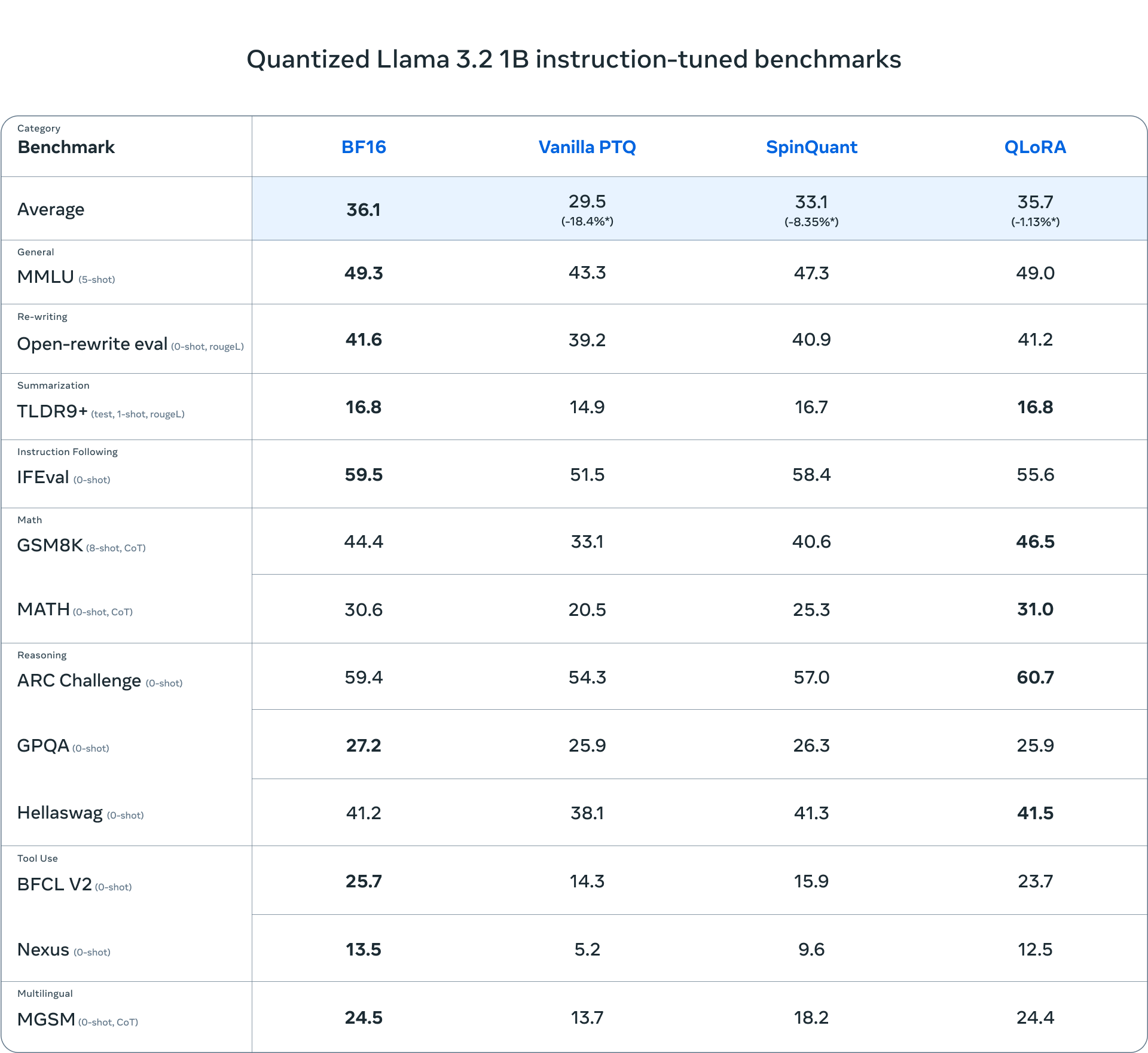
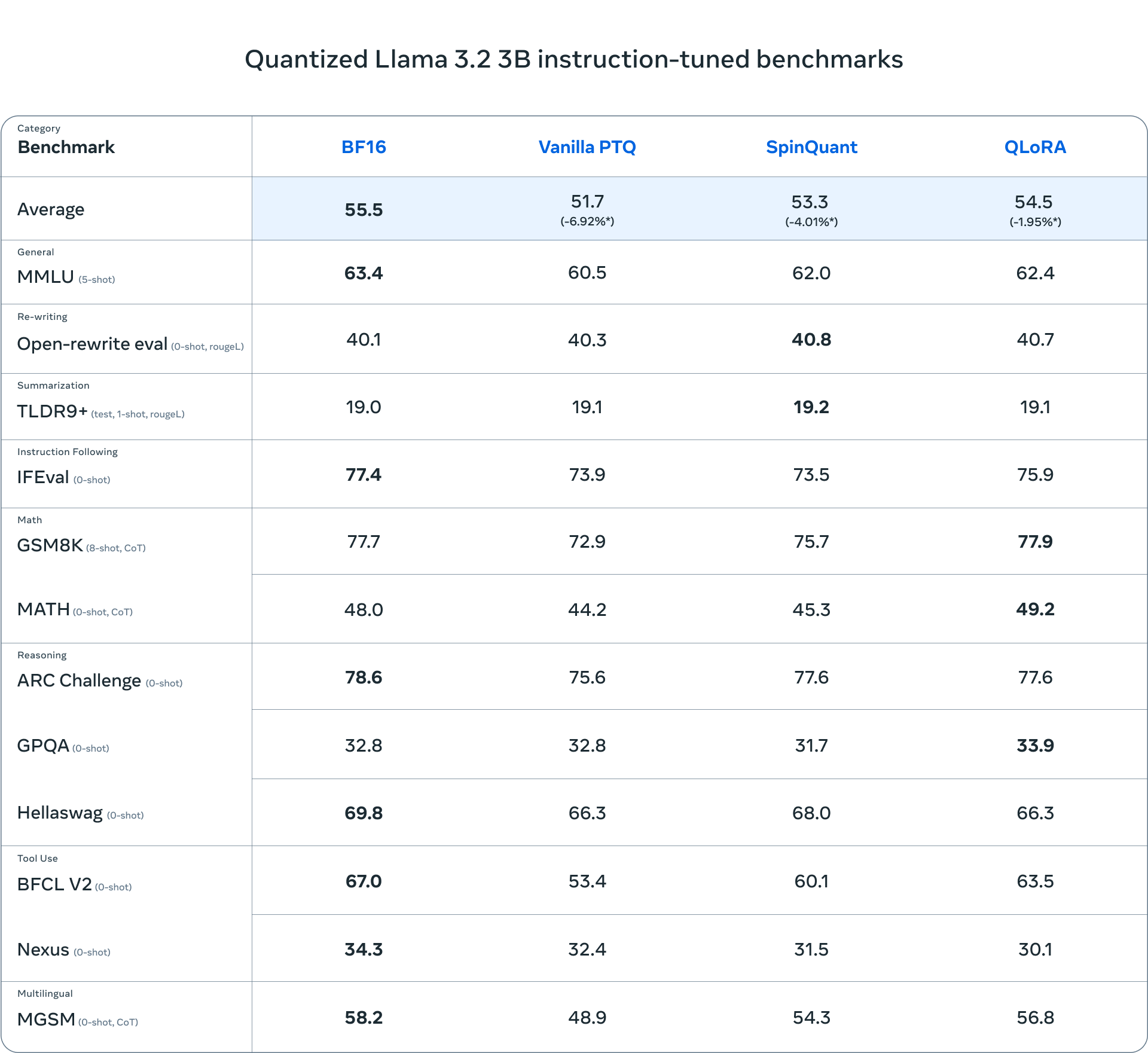
Vantaggi e risultati dei modelli quantizzati
I modelli quantizzati di Llama, basati sull’infrastruttura di PyTorch ExecuTorch e ottimizzati con il supporto della libreria Kleidi AI, offrono prestazioni ottimali su dispositivi mobili. I test effettuati su dispositivi come OnePlus 12 e Samsung S24+ hanno evidenziato tempi di risposta nettamente migliorati: la latenza di decodifica è migliorata di 2,5 volte e la latenza di pre-riempimento è aumentata di 4,2 volte, rispetto al formato originale BF16. Per i dispositivi iOS, i modelli hanno dimostrato una precisione paragonabile, sebbene la velocità non sia ancora stata completamente ottimizzata.
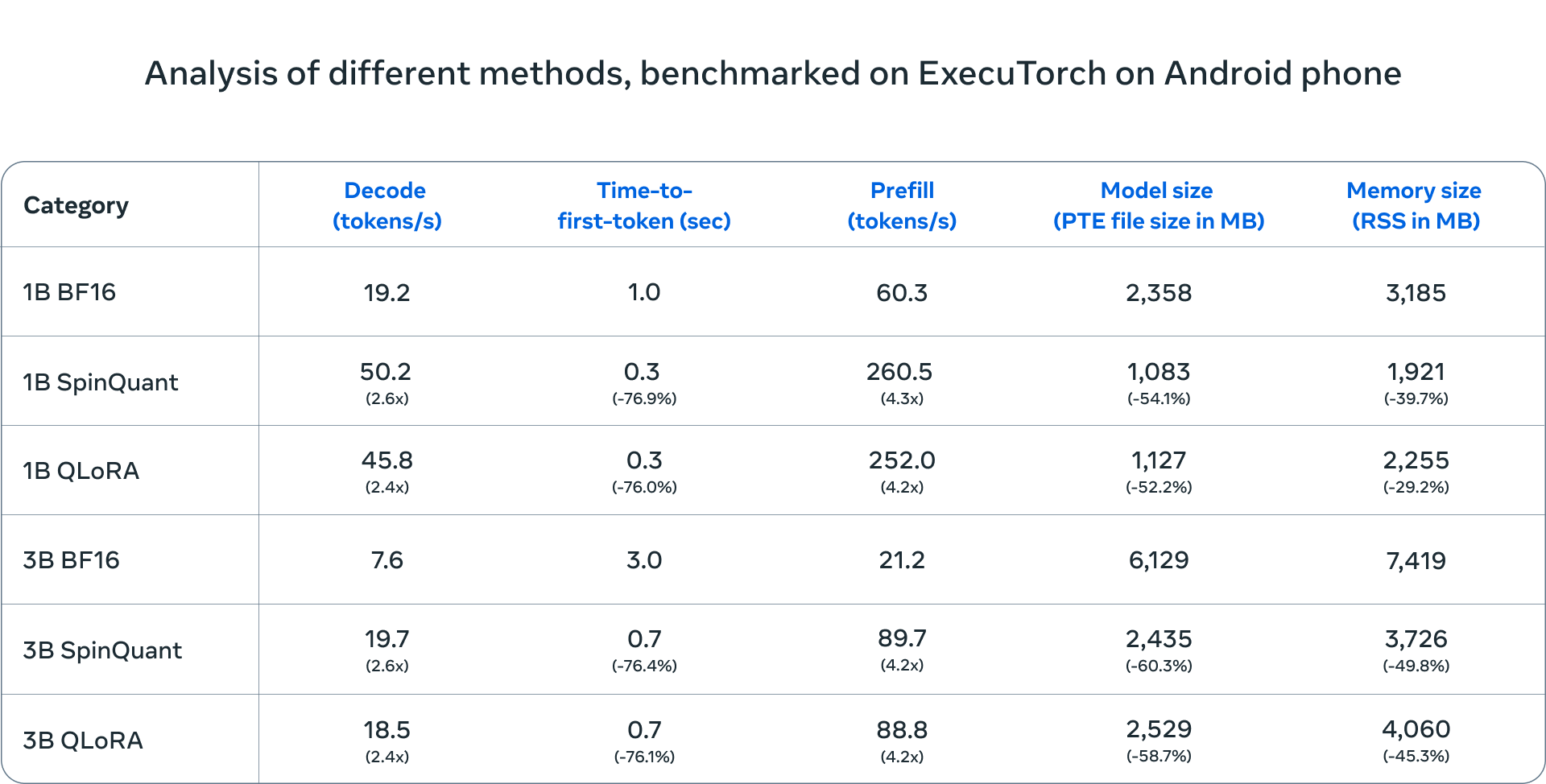
Un ulteriore passo avanti è rappresentato dal lavoro in corso per ottimizzare i modelli anche su NPU (Neural Processing Units), che potrebbero portare a prestazioni ancora migliori su dispositivi mobili e garantire una maggiore efficienza in contesti di intelligenza artificiale a bordo dispositivo.


Audible: 3 mesi a 0,99€
Super offerta per gli audilibri e non solo Amazon Audible: 3 mesi a 0,99€ al mese
Verso un futuro più accessibile per l’AI su dispositivi mobili
L’obiettivo dichiarato di Meta è facilitare l’adozione di AI avanzate anche su quei dispositivi, come gli smartphone, che non dispongono di grandi risorse computazionali, promuovendo così lo sviluppo di esperienze utente più rapide e sicure, in cui i dati rimangono sul dispositivo dell’utente, garantendo maggiore privacy. Grazie a questa nuova generazione di modelli quantizzati, Meta sta quindi fornendo ai developer strumenti sempre più performanti per creare applicazioni innovative e di qualità, accessibili anche su dispositivi mobili di uso comune.
I modelli sono disponibili su HuggingFace e su llama.com.
Ovviamente questo annuncio va a braccetto con un altro passo in avanti in ambito computazionale mobile, ovvero il lancio del nuovo Qualcomm Snapdragon 8 Elite che promette prestazioni superiori e il supporto a modelli AI fino a 12 miliardi di parametri, indubbiamente abilitante a potenzialità ancora tutte da scoprire.
I nostri contenuti da non perdere:
- 🔝 Importante: I migliori smartwatch per qualità prezzo di Aprile 2025
- 💰 Risparmia sulla tecnologia: segui Prezzi.Tech su Telegram, il miglior canale di offerte
- 🏡 Seguici anche sul canale Telegram Offerte.Casa per sconti su prodotti di largo consumo